How to scrape Website using Python BeautifulSoup?
Data scraping is a method to get data from the websites for business purposes, analyzing and countless purposes used by businessmen and programmers.
Python provides best of tools and libraries for carrying out data scraping work. In this tutorial, We’ll see how to scrape a table on a website using Python’ s libraries & with a very simple coding.
Download PDF of this Tutorial on Web Scraping using BeautifulSoup Downloaded 163 Times
1.Install BeautifulSoup Python Library
First, We have to install libraries Bs4, requests and lxml. You can install these libraries with this command run on the command prompt.
$ pip install requests $ pip install bs4 $ pip install lxml (Note – In windows OS, you don’t need to have $ sign.)
Once you’ve completed installing all libraries, We can move to the coding part.
2. Website Data To be Scrapped to Excel
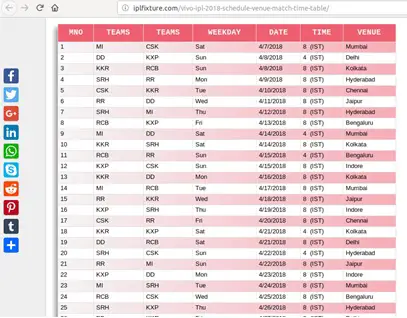
This is the table We’re hoping to scrape and, save it as csv file as a table.
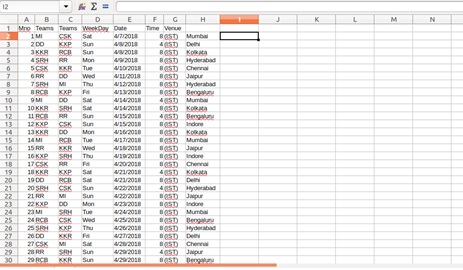
This is how it looks like on our csv file after extracting data.
3. Python Code to Scrape Website Data
Ready to do the trick? Well then, better start coding. First you have to choose an IDE for coding with python.
You can use Sublime text or some text editor you’re familiar with. (Hopefully, not the notepad.) The IDE I’m using is PyCharm Community. If you’re hoping to carry out more python developing, I suggest you install this.
Get HTML Table Name: Now it’s time to have basic knowledge about inside of a website. As we know, a website is made of elements, which were defined with a language called HTML. In this website’s elements, There is the one we need to scrape.
- You can view the elements of a website by pressing F12.
- Now we have to find the element that represent the table that we need to scrape.
- You can see the <tbody> tag surrounds the whole table we need. Now, let’s go get it!
Here is the Python code snippet to extract the Table in Website to Excel, Let’s get the code explained.
# Pyton Library for send HTTP requests
import requests
# Python library for handling parsed content
from bs4 import BeautifulSoup
# Csv file handling library for python
import csv
# Method to send HTTP request and get html content.
link = 'http://iplfixture.com/vivo-ipl-2018-schedule-venue-match-time-table/'
def connection(link):
page = requests.get(link)
soup = BeautifulSoup(page.content,'lxml')
return soup
# Called the method
table = connection(link).find('table',{'id':'tabcust'})
tr = table.find('tbody').find_all('tr')
# Using a for loop for get each <td> tag within the <tr> tag.
for t in tr:
td = (str(t.text).replace('\n',' ')).split()
print td
# We have the table's each row now.
# Now we have to get each <td> tag out separately to append to our excel table.
# Writing data to the csv file.
resultFile = open("out.csv", 'ab')
wr = csv.writer(resultFile, dialect='excel')
wr.writerow(td)
resultFile.close()
I assume you have python installed, and the basic knowledge of Python, to execute a program & install libraries with pip.
These tutorials are based on Python 2.7.12, However the Python 3.X versions shows the same syntax on this parts.